ai.stanford.edu/blog/linkbert
Preview meta tags from the ai.stanford.edu website.
Linked Hostnames
19- 36 links toai.stanford.edu
- 17 links toarxiv.org
- 4 links togithub.com
- 2 links tocs.stanford.edu
- 2 links totwitter.com
- 1 link toblog.google
- 1 link toen.wikipedia.org
- 1 link togetpocket.com
Thumbnail
Search Engine Appearance
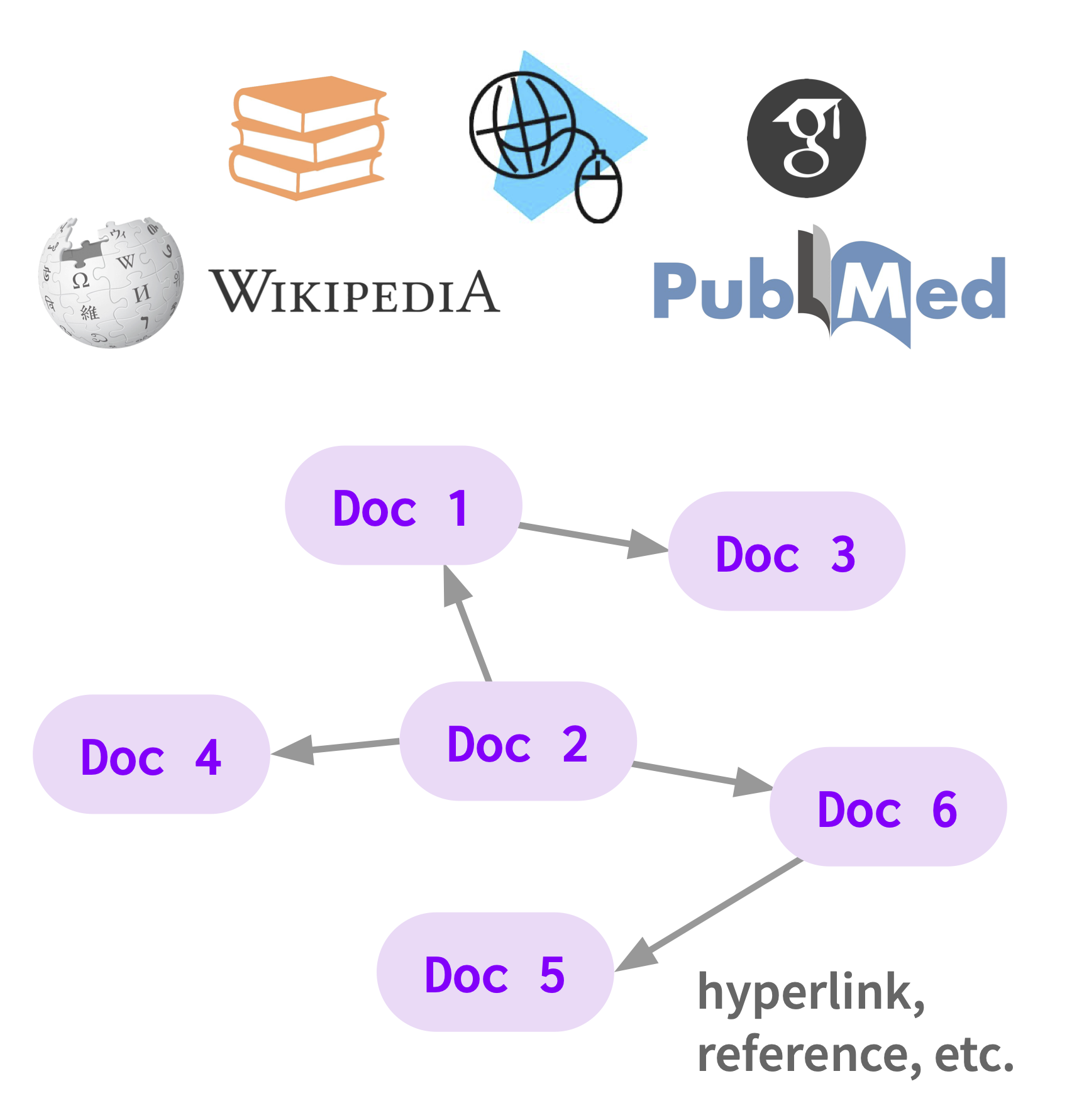
LinkBERT: Improving Language Model Training with Document Link
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2, achieve remarkable performance on many natural language processing (NLP) tasks. They are now the foundation of today’s NLP systems. 3 These models serve important roles in products and tools that we use every day, such as search engines like Google 4 and personal assistants like Alexa 5. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. 2019. ↩ Language Models are Few-Shot Learners. Tom B. Brown, et al. 2020. ↩ On the Opportunities and Risks of Foundation Models. Rishi Bommasani et al. 2021. ↩ Google uses BERT for its search engine: https://blog.google/products/search/search-language-understanding-bert/ ↩ Language Model is All You Need: Natural Language Understanding as Question Answering. Mahdi Namazifar et al. Alexa AI. 2020. ↩
Bing
LinkBERT: Improving Language Model Training with Document Link
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2, achieve remarkable performance on many natural language processing (NLP) tasks. They are now the foundation of today’s NLP systems. 3 These models serve important roles in products and tools that we use every day, such as search engines like Google 4 and personal assistants like Alexa 5. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. 2019. ↩ Language Models are Few-Shot Learners. Tom B. Brown, et al. 2020. ↩ On the Opportunities and Risks of Foundation Models. Rishi Bommasani et al. 2021. ↩ Google uses BERT for its search engine: https://blog.google/products/search/search-language-understanding-bert/ ↩ Language Model is All You Need: Natural Language Understanding as Question Answering. Mahdi Namazifar et al. Alexa AI. 2020. ↩
DuckDuckGo
https://ai.stanford.edu/blog/linkbertLinkBERT: Improving Language Model Training with Document Link
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2, achieve remarkable performance on many natural language processing (NLP) tasks. They are now the foundation of today’s NLP systems. 3 These models serve important roles in products and tools that we use every day, such as search engines like Google 4 and personal assistants like Alexa 5. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. 2019. ↩ Language Models are Few-Shot Learners. Tom B. Brown, et al. 2020. ↩ On the Opportunities and Risks of Foundation Models. Rishi Bommasani et al. 2021. ↩ Google uses BERT for its search engine: https://blog.google/products/search/search-language-understanding-bert/ ↩ Language Model is All You Need: Natural Language Understanding as Question Answering. Mahdi Namazifar et al. Alexa AI. 2020. ↩
General Meta Tags
11- titleLinkBERT: Improving Language Model Training with Document Link | SAIL Blog
- titleLinkBERT: Improving Language Model Training with Document Link | The Stanford AI Lab Blog
- charsetutf-8
- viewportwidth=device-width, initial-scale=1, maximum-scale=1
- generatorJekyll v3.9.0
Open Graph Meta Tags
6- og:titleLinkBERT: Improving Language Model Training with Document Link
 og:localeen_US
og:localeen_US- og:descriptionLanguage Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2, achieve remarkable performance on many natural language processing (NLP) tasks. They are now the foundation of today’s NLP systems. 3 These models serve important roles in products and tools that we use every day, such as search engines like Google 4 and personal assistants like Alexa 5. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. 2019. ↩ Language Models are Few-Shot Learners. Tom B. Brown, et al. 2020. ↩ On the Opportunities and Risks of Foundation Models. Rishi Bommasani et al. 2021. ↩ Google uses BERT for its search engine: https://blog.google/products/search/search-language-understanding-bert/ ↩ Language Model is All You Need: Natural Language Understanding as Question Answering. Mahdi Namazifar et al. Alexa AI. 2020. ↩
- og:urlhttp://ai.stanford.edu/blog/linkbert/
- og:site_nameSAIL Blog
Twitter Meta Tags
6- twitter:cardsummary
- twitter:titleLinkBERT: Improving Language Model Training with Document Link
- twitter:descriptionLinkBERT: Improving Language Model Training with Document Link
- twitter:creator@StanfordAILab
- twitter:cardsummary_large_image
Link Tags
13- alternatehttp://ai.stanford.edu/blog/feed.xml
- canonicalhttp://ai.stanford.edu/blog/linkbert/
- canonicalhttp://ai.stanford.edu/blog/linkbert/
- icon/blog/assets/img/favicon-32x32.png
- icon/blog/assets/img/favicon-16x16.png
Emails
1- ?subject=LinkBERT%3A+Improving+Language+Model+Training+with+Document+Link%20%7C%20SAIL+Blog&body=:%20http://ai.stanford.edu/blog/linkbert/
Links
75- http://ai.stanford.edu
- http://ai.stanford.edu/blog/feed.xml
- http://arxiv.org/abs/2203.15827
- http://www.reddit.com/submit?url=http://ai.stanford.edu/blog/linkbert/&title=LinkBERT%3A+Improving+Language+Model+Training+with+Document+Link%20%7C%20SAIL+Blog
- https://ai.stanford.edu/blog