blog.tensoropera.ai/fedml-nexus-ai-unlocks-llama-7b-pre-training-and-fine-tuning-on-geo-distributed-rtx4090s
Preview meta tags from the blog.tensoropera.ai website.
Linked Hostnames
5- 7 links toblog.tensoropera.ai
- 2 links toarxiv.org
- 1 link toghost.org
- 1 link togithub.com
- 1 link totensoropera.ai
Thumbnail
Search Engine Appearance
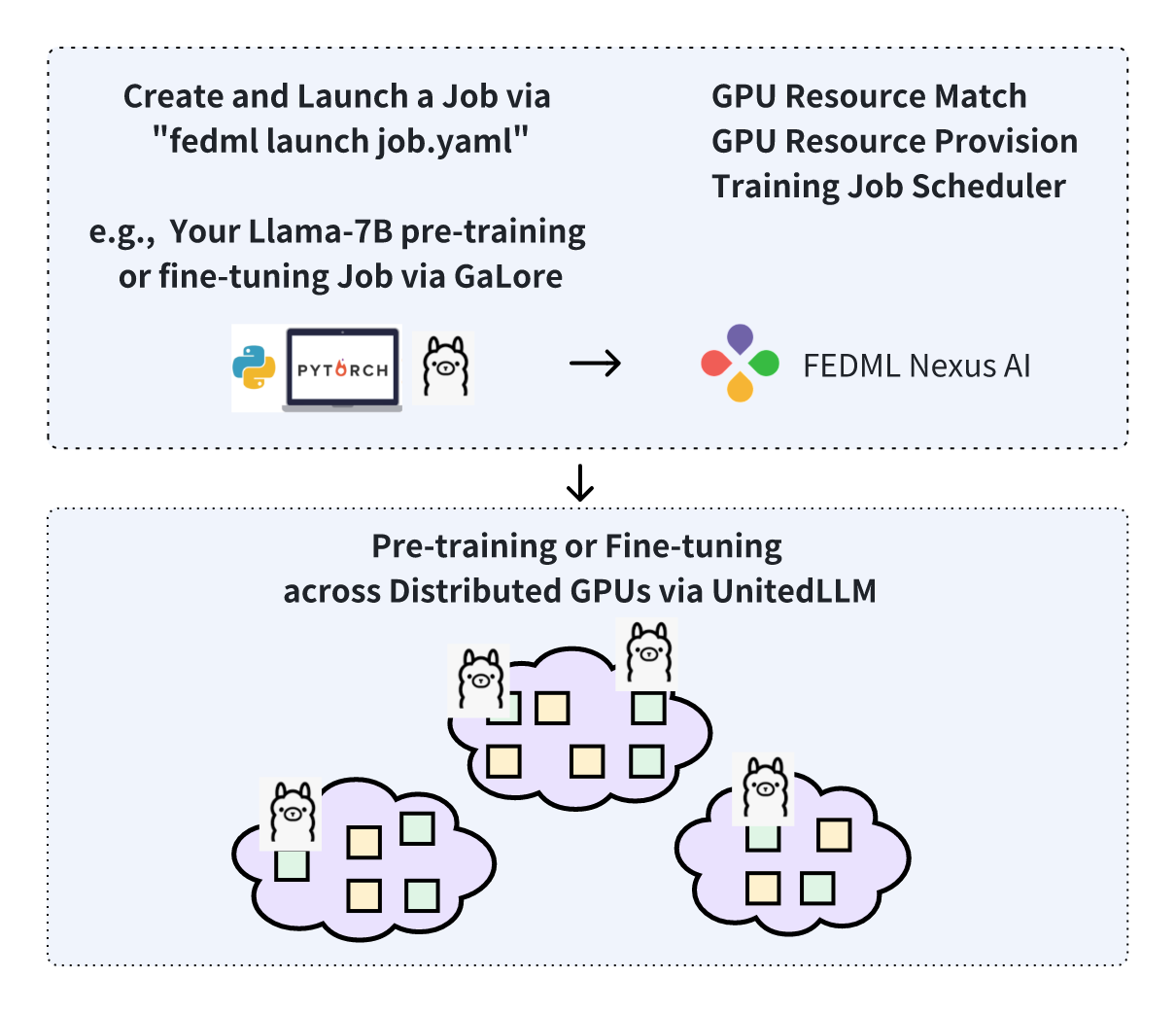
FEDML Nexus AI Unlocks LLaMA-7B Pre-Training and Fine-tuning on Geo-distributed RTX4090s
Since 2020, the machine learning (ML) community has experienced an exponential surge in large language model (LLM) sizes, escalating from 175 billion to a remarkable 10 trillion parameters in just three years. This rapid expansion has led to significant bottlenecks for AI developers, notably in the availability of GPUs, escalating
Bing
FEDML Nexus AI Unlocks LLaMA-7B Pre-Training and Fine-tuning on Geo-distributed RTX4090s
Since 2020, the machine learning (ML) community has experienced an exponential surge in large language model (LLM) sizes, escalating from 175 billion to a remarkable 10 trillion parameters in just three years. This rapid expansion has led to significant bottlenecks for AI developers, notably in the availability of GPUs, escalating
DuckDuckGo
FEDML Nexus AI Unlocks LLaMA-7B Pre-Training and Fine-tuning on Geo-distributed RTX4090s
Since 2020, the machine learning (ML) community has experienced an exponential surge in large language model (LLM) sizes, escalating from 175 billion to a remarkable 10 trillion parameters in just three years. This rapid expansion has led to significant bottlenecks for AI developers, notably in the availability of GPUs, escalating
General Meta Tags
8- titleFEDML Nexus AI Unlocks LLaMA-7B Pre-Training and Fine-tuning on Geo-distributed RTX4090s
- charsetutf-8
- viewportwidth=device-width, initial-scale=1
- referrerno-referrer-when-downgrade
- article:published_time2024-03-21T19:59:30.000Z
Open Graph Meta Tags
8- og:site_nameTensorOpera AI Blog
- og:typearticle
- og:titleFEDML Nexus AI Unlocks LLaMA-7B Pre-Training and Fine-tuning on Geo-distributed RTX4090s
- og:descriptionSince 2020, the machine learning (ML) community has experienced an exponential surge in large language model (LLM) sizes, escalating from 175 billion to a remarkable 10 trillion parameters in just three years. This rapid expansion has led to significant bottlenecks for AI developers, notably in the availability of GPUs, escalating
- og:urlhttps://blog.tensoropera.ai/fedml-nexus-ai-unlocks-llama-7b-pre-training-and-fine-tuning-on-geo-distributed-rtx4090s/
Twitter Meta Tags
9- twitter:cardsummary_large_image
- twitter:titleFEDML Nexus AI Unlocks LLaMA-7B Pre-Training and Fine-tuning on Geo-distributed RTX4090s
- twitter:descriptionSince 2020, the machine learning (ML) community has experienced an exponential surge in large language model (LLM) sizes, escalating from 175 billion to a remarkable 10 trillion parameters in just three years. This rapid expansion has led to significant bottlenecks for AI developers, notably in the availability of GPUs, escalating
- twitter:urlhttps://blog.tensoropera.ai/fedml-nexus-ai-unlocks-llama-7b-pre-training-and-fine-tuning-on-geo-distributed-rtx4090s/
- twitter:imagehttps://blog.tensoropera.ai/content/images/size/w1200/2024/03/image-15-1.png
Link Tags
6- alternatehttps://blog.tensoropera.ai/rss/
- canonicalhttps://blog.tensoropera.ai/fedml-nexus-ai-unlocks-llama-7b-pre-training-and-fine-tuning-on-geo-distributed-rtx4090s/
- iconhttps://blog.tensoropera.ai/content/images/size/w256h256/2023/04/FedML_logo.png
- stylesheethttps://blog.tensoropera.ai/assets/built/screen.css?v=fd7c36c2ca
- stylesheet/public/cards.min.css?v=fd7c36c2ca
Links
12- https://TensorOpera.ai
- https://arxiv.org/abs/1811.03617?ref=blog.tensoropera.ai
- https://arxiv.org/pdf/2308.06522.pdf?ref=blog.tensoropera.ai
- https://blog.tensoropera.ai
- https://blog.tensoropera.ai/author/https-fedml-ai